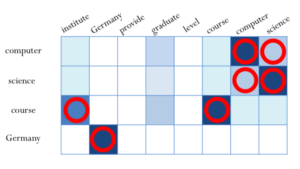
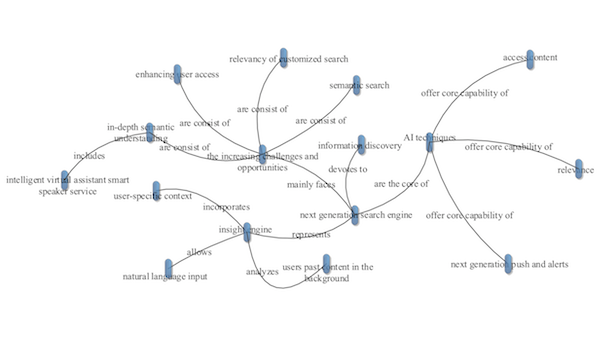
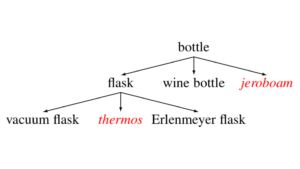
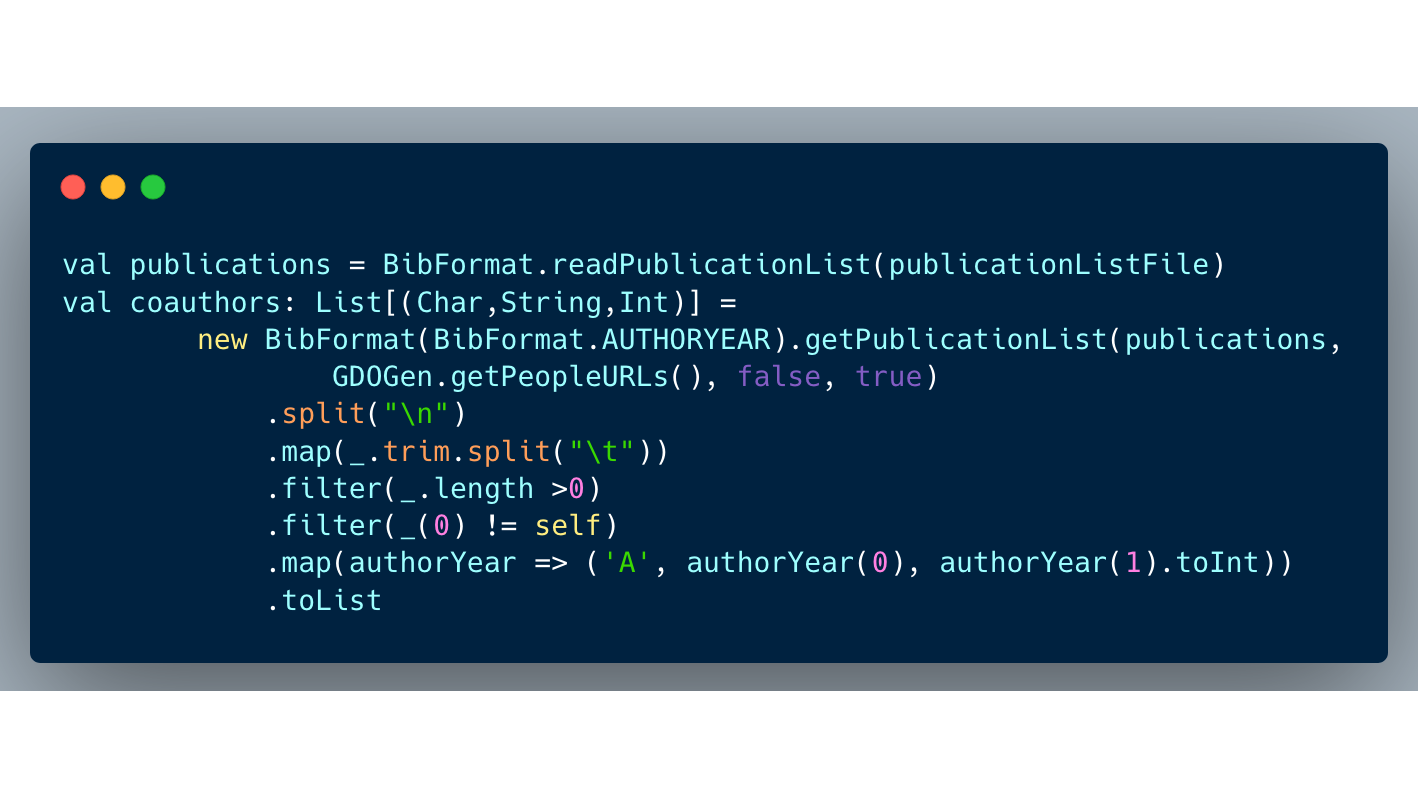
Knowledge and Data Resources

Our book on knowledge graphs teaches both fundamental principles and current trends. It is available to purchase but also freely browsable online.

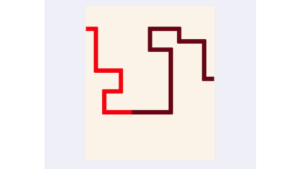
FrameBase uses frame semantics, a theory of natural language semantics, to represent knowledge about the world in a consistent way.

Large amounts of common-sense knowledge extracted from the Web.
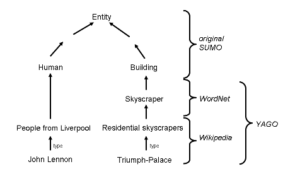
An ontology providing an enormous body of axiomatized world knowledge based on YAGO as well as the Suggested Upper Merged Ontology (SUMO).
YAGO was used in IBM's famous Jeopardy!-winning system Watson.
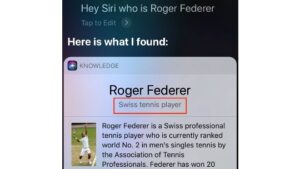
Source code for a deep learning-based system that generates natural language descriptions of entities, along with corresponding benchmark datasets (based on Wikidata).
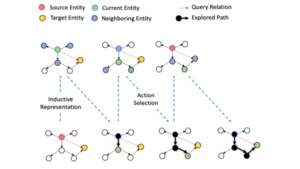
Benchmark datasets for knowledge graph completion in an inductive setting (previously unseen entities in test set): WN18RR-Inductive, FB15k-237-Inductive, NELL-995-Inductive.
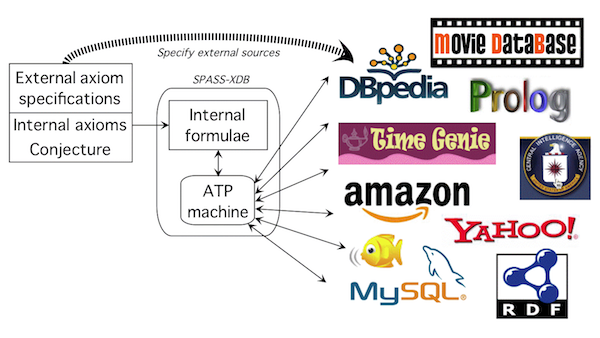
Online interface to the SPASS-XDB reasoning system, which combines state-of-the-art theorem proving with support for large-scale knowledge sources.

File Viewer (for DOS) supporting over 400 different file formats.