Gerard de Melo's Research while at ICSI, Berkeley

See homepage for current contact information and further details.
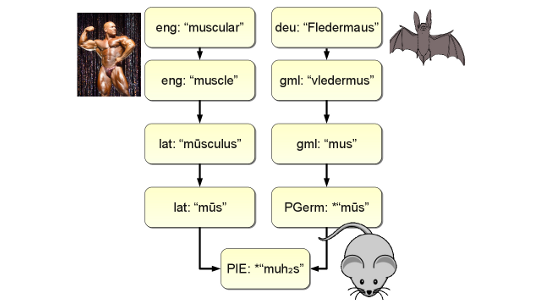
A database of etymological and derivational relationships between words in different languages.
Non-1-to-1 alignments of word senses from two inventories visualized. See also our Blog post about this project.
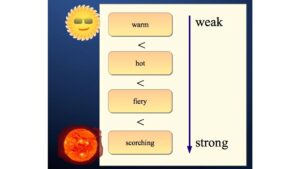
System that scores the relative intensities of different words.
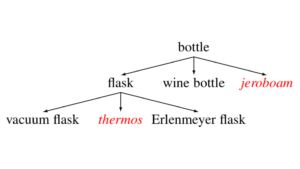
An open-domain taxonomy prediction benchmark dataset covering a much more diverse set of domains than previous datasets.
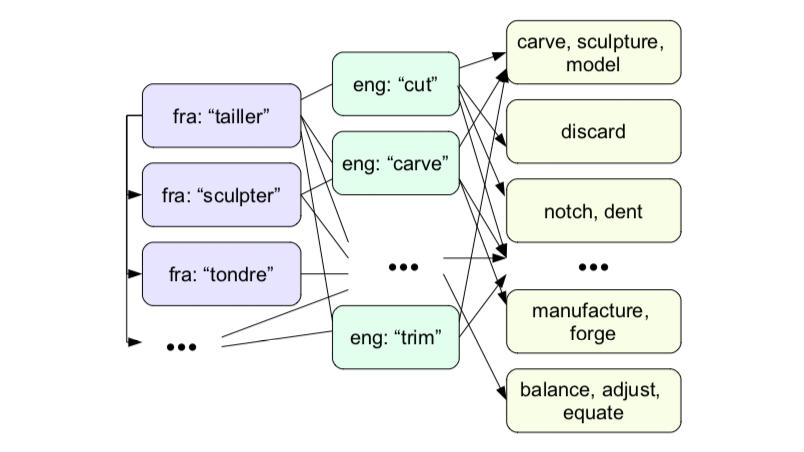
Thesauri in many languages, obtained by translating Roget's Thesaurus using task-specific statistical techniques

A new more user-friendly browsing interface for the FrameNet lexical semantic resource, which describes the semantic roles of sentences and words.

FrameBase uses frame semantics, a theory of natural language semantics, to represent knowledge about the world in a consistent way. I also developed a new browsing interface for the FrameNet lexical resource, which FrameBase relies on.

Large amounts of common-sense knowledge extracted from the Web.
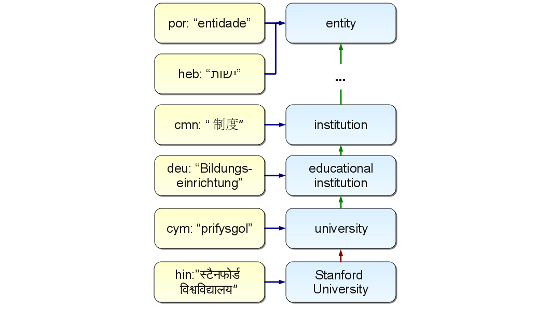
One of the largest multilingual knowledge graphs, transforming the well-known WordNet database into a massively multilingual resource covering over 1 million words and several million named entities in a single semantically organized hierarchy.
This is based on machine learning along with the MENTA extension based on Wikipedia.
Our derivative project OpenWordNet-PT (GitHub) is being used by Google Translate.
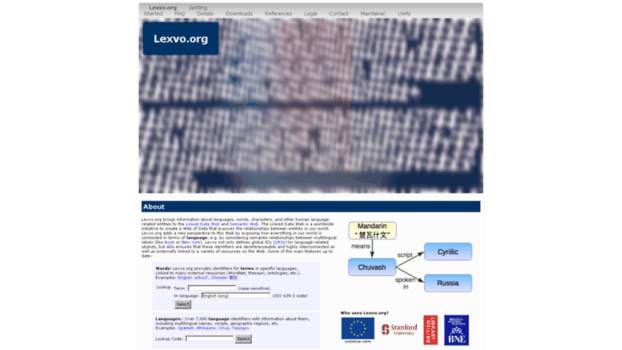
Contributes information about words and other language-related entities to the Linked Data Web and Semantic Web, leading to a Web of Data in which the British Library, the Spanish National Library, and others have linked their data to Lexvo.org, and Lexvo.org in turn connects its own data to other valuable resources.
Most research papers are freely available (open access).
Numerous other resources are available.